RAGtronic started as a question: what would an AI backend look like if you built it the way enterprise infrastructure demands, observable, multi-tenant, zero-trust, and designed to degrade gracefully when individual components fail?
Most AI backends are Python scripts wrapped around an API call. RAGtronic is something different: ~28,000 lines of Rust powering a multi-model orchestration layer, a content safety pipeline with automatic degradation, per-tenant RAG isolation, and an OpenAI-compatible gateway that lets any tool in the ecosystem talk to it natively. It runs as part of a broader AI infrastructure stack, one of many services across 70+ containers on a Proxmox virtualisation cluster.
An obvious question: why Docker Compose and not Kubernetes? The answer is that this is a deliberate architectural choice, not a limitation. I run Kubernetes elsewhere in the lab for other workloads (and have written about it), but the AI stack has a specific constraint that makes Compose the better fit right now. The entire stack runs on a dedicated Proxmox VM with 64GB of RAM, 16 vCPUs across dual Xeon Gold 6138 processors, and an NVIDIA Quadro M6000 24GB passed through via PCI-e. That single GPU handles local model inference, embedding generation, and GPU-accelerated document processing. With one GPU dedicated to one workload, the scheduling and device-sharing complexity that Kubernetes brings (GPU operator, time-slicing, MIG partitioning) adds overhead without adding value. Compose gives me faster iteration cycles, instant hot-reload during development, and a deployment model where every container is already defined with the right GPU reservations, volume mounts, and network policies. The stack is fully containerised with no host dependencies, so the path to Kubernetes is there whenever the workload demands it, a second GPU, multi-node scaling, or automated failover across hosts. Until then, Compose keeps the complexity proportional to the problem.
This post covers the architecture, the decisions behind it, and some of the more interesting engineering challenges, like making a model that was never trained on Creole actually hold a conversation in it, and giving the whole thing an authentic Aussie personality through edge-layer prompt engineering.
Oh, and if you want to skip straight to testing: that AI assistant button on this site? That's RAGtronic. You're looking at the production system right now. Go ahead, ask it something.
The Migration: Python to Rust
RAGtronic didn't start as Rust. The first version was Python, FastAPI, the usual stack. It worked, but as the feature set grew, the problems compounded: memory usage climbing with each concurrent stream, GC pauses interrupting SSE responses mid-token, and a general unease about deploying something that consumed 500MB+ at idle for what was essentially a proxy with business logic.
The rewrite to Rust with Actix-web was motivated by three things:
-
Streaming fidelity: When you're proxying Server-Sent Events from an LLM, every pause matters. Garbage collection pauses during streaming create visible stutters in the frontend. Rust's zero-cost abstractions and lack of GC eliminate this entirely.
-
Resource predictability: The Rust backend idles at ~50MB. On shared infrastructure where every container competes for memory, this matters. The Python version consumed 10x that before handling a single request.
-
Compile-time guarantees: Every API contract, every database query shape, every serialisation boundary is checked before deployment. When you're running a platform where a malformed response can cascade into a broken UI, the compiler is the most cost-effective QA engineer you'll ever hire.
The Python version still exists as a python-legacy branch. The NeMo Guardrails service, which couldn't be ported to Rust because it's tightly coupled to NVIDIA's Python runtime, became a sidecar instead. That constraint turned into one of the better architectural decisions in the project.
Architecture Overview
RAGtronic runs as a containerised stack orchestrated with Docker Compose. The core principle is separation of concerns: authentication lives outside the application, content safety runs as a sidecar, model routing goes through a dedicated proxy, and the Rust backend focuses purely on business logic.

Every component is independently deployable and replaceable. The backend doesn't know how authentication works, it receives pre-validated headers. It doesn't know which LLM provider is active, it talks to a unified proxy. It doesn't know the specifics of content safety rules, it calls a sidecar and respects the verdict. This separation has paid dividends: I've swapped LLM providers, updated guardrail rules, and rotated auth configurations without touching backend code.
Dual Access Profiles
RAGtronic exposes two distinct access profiles for the backend, a design pattern borrowed from how platforms like Splunk separate management ports from data ingestion ports:
| Port | Profile | Purpose |
|---|---|---|
| 8888 | External (Public) | Customer-facing API, routed through Cloudflare Workers for edge security, rate limiting, and DDoS protection before hitting Traefik. Guardrails are enforced on every request. |
| 8889 | Internal (Admin) | Direct LAN access for internal integrations, Open WebUI, admin tooling, debugging. Serves an OpenAI-compatible endpoint that any tool in the ecosystem can connect to. |
| 4459 | Gateway | Ory Oathkeeper proxy, all authenticated frontend traffic flows through here for session validation and header injection. |
Both ports map to the same Rust process on port 8080 inside the container. The difference is what sits in front of each.
Why two profiles? Because the same RAG pipeline serves two fundamentally different use cases. The external profile powers a public-facing AI assistant on a website, rate-limited, guardrailed, cost-tracked. The internal profile reuses that same RAG context (the same vector collections, the same prompt configurations) but exposes it as an OpenAI-compatible endpoint for internal consumption. Point Open WebUI at it, connect Cursor or Continue.dev, wire up a LangChain pipeline, it speaks the same protocol. One RAG investment, two access patterns.
How the Frontend Chat Actually Works
When you type a message into the chat bar on ozteklab.com, a lot happens in a very short window. Here's the end-to-end flow:

The frontend is a Next.js application running on a production server. The chat bar sends messages to a local API route (/api/chat), which acts as a thin proxy. That proxy forwards the request to portfolio-api.ozteklab.com, the RAGtronic backend's public endpoint, secured behind a Cloudflare Access tunnel. Every request includes Cloudflare Access service tokens (CF-Access-Client-Id and CF-Access-Client-Secret) for Zero Trust authentication at the edge, before the request ever reaches the origin server.
The backend (RAGtronic) then runs through a multi-stage pipeline:
- Qdrant vector search queries the document embeddings. If relevant context is found, the prompt is augmented with the retrieved chunks (RAG retrieval). If not, the query proceeds directly without context injection.
- Internal source verification checks whether the request originated from a verified internal source (such as a code block rendered on the blog itself). Verified internal content bypasses the content safety layer, since it's our own code being explained. Regular user chat messages always go through the full safety pipeline.
- NeMo Guardrails evaluates unverified requests for content safety. Anything that violates the safety policy is blocked before it ever reaches a model.
- LiteLLM proxy dispatches the approved request to whichever model is configured for that tenant. The model doing the actual inference could be anything in the catalogue: a Cloudflare Workers AI model like Llama 4 Scout or DeepSeek-R1-Distill-Qwen-32B running at the edge, a self-hosted Ollama model like Gemma 3 or Qwen2.5-Coder running on the lab GPU, or a cloud API model from Anthropic, OpenAI, or DeepSeek.
The response then streams back through the same path: model output flows through LiteLLM, back through the RAGtronic API gateway, through the Cloudflare tunnel, through the Next.js proxy route, and into the ChatSidebar component where it's rendered as markdown.
This is the key architectural insight: Cloudflare sits in front, providing edge security and Zero Trust access control. RAGtronic sits behind it, handling all the intelligence: RAG retrieval, prompt engineering, content safety, and model orchestration. The model that ultimately generates the response is completely swappable, configurable per-tenant from the admin dashboard. The frontend doesn't know or care which model is active. It sends a message and gets a response. The entire model layer is abstracted away behind RAGtronic's unified API.
This same pattern scales to Dubstack: each documentation stack gets its own tenant configuration, its own RAG collections, and its own model selection, all running through the same RAGtronic backend.
Multi-Model Orchestration: 91 Models, 10 Providers
RAGtronic doesn't call LLM providers directly. All model traffic flows through a LiteLLM proxy which provides a unified interface across providers.
The current deployment has 91 unique models available across 10 providers:
| Provider | Models | Examples |
|---|---|---|
| Anthropic | 13 | Claude Opus 4.6, Sonnet 4.5, Haiku 4.5 |
| OpenAI | 17 | GPT-5.4, GPT-5.3-Codex, GPT-5.2-Codex, GPT-5-Codex, Codex Mini, GPT-OSS |
| 6 | Gemini 3 Pro Preview, Gemini 2.5 Pro, Flash | |
| DeepSeek | 6 | DeepSeek V3.2, V3.1, R1, Coder V2 |
| Qwen | 13 | Qwen3 Max, Qwen3-Coder Plus, Qwen3-235B |
| Kimi | 12 | Kimi K2, K2 Turbo, Moonshot v1 |
| Cloudflare AI | 12 | Llama 4 Scout, Llama 3.3 70B, QwQ-32B, Granite 4.0, DeepSeek-R1-Distill-Qwen-32B |
| Ollama | 6 | Gemma 3, Llama 3.1, Phi-4, Qwen2.5-Coder |
| GLM | 2 | GLM-4.6, GLM-4.5 |
| MiniMax | 2 | MiniMax M2 |
LiteLLM handles the complexity that would otherwise pollute the backend:
- Unified API surface: One endpoint, any model. The backend sends a standard chat completion request; LiteLLM routes it to the appropriate provider with the correct auth headers, API format, and token counting.
- Automatic failover: Models can be configured with fallback chains. If a primary model's API returns errors, LiteLLM automatically routes to the next in the chain. Some models have duplicate entries specifically for this, 93 total rows in the routing table for 91 unique models.
- Cost tracking: Per-request token counting and cost calculation across all providers. The admin dashboard surfaces this in real time.
- Key rotation and rate limit handling: Multiple API keys per provider with automatic retry and exponential backoff.
The admin UI lets operators configure providers, set default models per profile, and monitor spend in real time. Model selection happens at the profile level, so different AI profiles can target different models. A cost-conscious external-facing profile might use a smaller model while the internal research profile has access to the full catalogue.
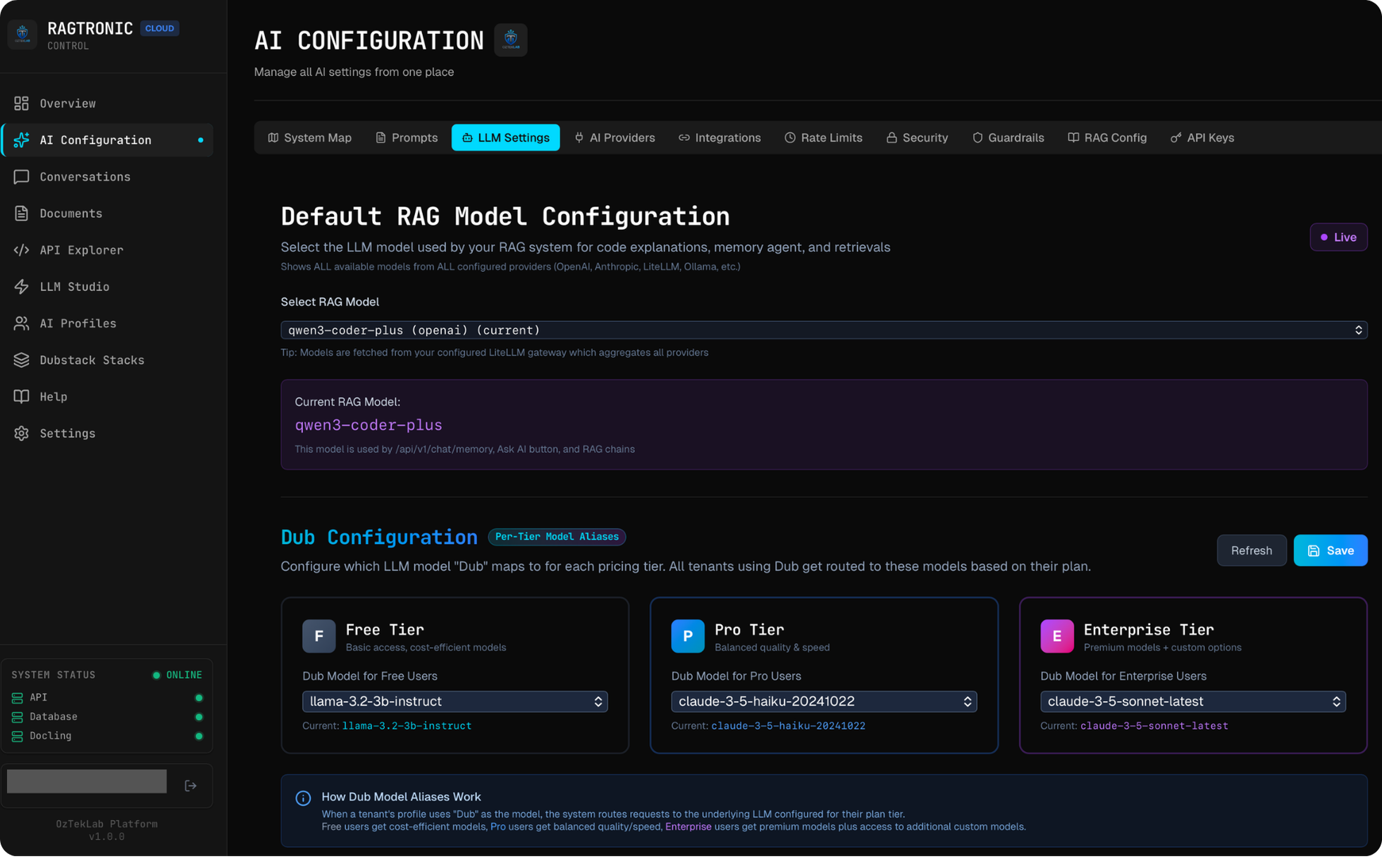
Content Safety: Dual-Layer Guardrails
Content safety is where RAGtronic's engineering gets interesting. Rather than bolting on a single safety check, the platform implements a dual-layer guardrails architecture with automatic degradation.
Layer 1: NVIDIA NeMo Guardrails (Primary)
The primary defence is an NVIDIA NeMo Guardrails sidecar, a Python service running alongside the Rust backend. NeMo Guardrails provides:
- Prompt injection detection: LLM-powered classification of whether an input is attempting to manipulate system behaviour
- Jailbreak attempt blocking: Pattern recognition and semantic analysis of adversarial prompts
- Output filtering: Post-generation validation to ensure responses don't contain sensitive data or harmful content
- Configurable Colang rules: Domain-specific safety policies defined in NVIDIA's Colang language, with custom actions for filtering
The guardrails sidecar calls LiteLLM for its own classification tasks, creating a defence-in-depth pattern: a separate LLM evaluates whether the user's prompt is safe before the main LLM processes it. This means the classification model and the generation model are independent, so compromising one doesn't compromise the other.
Layer 2: Compiled Pattern Engine (Fallback)
Here's the engineering problem: the NeMo sidecar is a separate process. It can go down. Network calls can time out. If your only safety layer is an external service, a sidecar restart means your platform is temporarily unprotected.
The Rust backend includes a compiled-in pattern matching engine as an automatic fallback. When the NeMo sidecar is unreachable (5-second timeout), the backend seamlessly switches to this engine, with no downtime and no unprotected requests.
The fallback engine includes pattern categories for injection attempts, adversarial token sequences, and unsafe content generation. Every input and output passes through validation, validate_input_for_chat() and validate_output_for_chat(), which try the NeMo sidecar first and fall back to pattern matching with a warning logged.
The health endpoint reports the current state:
Or in degraded mode:
Quick detour: See the sparkle icon on the code blocks above? That's the "Ask AI" button. Click it and the RAG pipeline will explain the code for you in real time. Every code block on this page is interactive, try it out while you read. For a better demo with more code to play with, check out the Persistent Lubuntu Desktop Workspaces post, it's packed with Terraform and shell scripts that the AI breaks down nicely.
Cryptographic Code Block Verification
Not every request should hit guardrails at full sensitivity. When a user clicks "Ask AI" on a code block in a blog post, the content might contain patterns that trigger injection detection, things like SQL queries, shell commands, regex patterns, or system administration snippets. These are legitimate code samples, not attack payloads, but a regex-based guardrail can't tell the difference.
The naive solution would be a client-side flag like skip_guardrails: true, but any flag controlled by the client can be spoofed with a single curl command. That turns a guardrail bypass into both a security vulnerability and a token abuse vector.
The platform solves this with HMAC-SHA256 signatures at render time. During server-side rendering, each code block is signed using a shared secret that exists only in the Next.js server environment and the Cloudflare Worker. The signature covers both the code content and the language identifier, so it's bound to the exact content that was rendered.
When the "Ask AI" request reaches the edge layer, the Cloudflare Worker recomputes the HMAC from the submitted code content and compares it to the signature. A match proves the code block was rendered by the application server, not injected by an external caller. Requests with missing or invalid signatures are rejected outright at the edge, before they consume any LLM tokens.
This design gives three properties:
- Zero manual effort: Every code block on every page is signed automatically during rendering. Write a blog post, deploy it, and every code block is immediately protected. No configuration per article, no allowlists.
- No bypass vector: The signing secret never reaches the browser. An attacker can inspect the DOM and extract a signature, but that signature only works for the exact code content it was generated from, so they can't forge a signature for arbitrary payloads.
- Token abuse prevention: Code block requests without a valid signature don't just fall through to relaxed guardrails, they're hard-rejected. This prevents external callers from burning API tokens by submitting arbitrary code blocks through the chat endpoint.
Why a Sidecar?
The guardrails sidecar wasn't a choice, it was a constraint that became an advantage. NeMo Guardrails is deeply embedded in the Python/NVIDIA ecosystem and can't be compiled to Rust. Running it as a sidecar means:
- Independent scaling: Guardrails can be horizontally scaled without touching the backend
- Hot-reload rules: Update Colang safety policies without redeploying the backend
- Failure isolation: A sidecar crash doesn't take down the backend (the fallback engine activates)
- Language flexibility: The right tool in the right runtime: Python for ML classification, Rust for request handling
Teaching LLMs Mauritian Creole
This is probably the most personally meaningful feature in RAGtronic.
Mauritian Creole (Kreol Morisien) is my native language. It's spoken by roughly 1.3 million people. Most large language models have never been trained on it. They'll either refuse to respond in Creole, confuse it with Haitian Creole, or produce grammatically incorrect output that sounds like a translation phrasebook.
RAGtronic solves this through RAG, specifically by ingesting a comprehensive linguistic corpus and making it available as retrieval context:
The Corpus
- 33,774 dictionary entries from the Lalit Mauritian Creole dictionary, the most comprehensive Kreol Morisien lexicon available
- 21 chunked index files organised alphabetically for efficient vector retrieval
- A critical differentiation document that explicitly maps the grammatical differences between Haitian Creole and Mauritian Creole, covering pronoun systems, verb conjugation patterns, key expressions, and structural divergences
That last document is particularly important. Without it, models default to Haitian Creole patterns when they detect "Creole" in the context, because Haitian Creole has significantly more training data representation. The differentiation document acts as a linguistic anchor that keeps the model grounded in the correct variant.
Language Detection and Prompt Injection
The profile middleware includes a Kreol language detector, a keyword-based system that recognises Mauritian Creole markers in user input (words like mo, to, li, nou, zot, koze, bonzour, ki manyer). When Creole is detected and the active profile has Creole mode enabled, the system injects a specialised prompt:
"The user is communicating in Mauritian Creole (Kreol Morisien). Respond in Mauritian Creole..."
This prompt, combined with the RAG context from the dictionary corpus, gives a model enough linguistic scaffolding to construct grammatically correct Kreol Morisien responses, even when the model was never trained on the language.
The result: you can plug in any model in the catalogue and have a conversation in Mauritian Creole. The real power of this approach shows with models that have zero Kreol in their training data: self-hosted Ollama models like Qwen2.5-Coder, Phi-4, Gemma 3, or Yi-Coder, and edge-deployed Cloudflare Workers AI models like DeepSeek-R1-Distill-Qwen-32B. These models would otherwise refuse to respond in Creole or produce garbled output. With the RAG dictionary corpus providing the linguistic scaffolding, they produce grammatically correct Kreol Morisien responses. The architecture is model-agnostic by design: swap in any provider, any model, and the same RAG context bridges the gap. It's not going to pass for a native speaker in long-form prose, but for conversational exchanges, it works remarkably well.
Demo Mode Interaction
Creole mode is disabled when Demo Mode is active (is_creole_enabled() checks enable_creole && !demo_mode). This ensures public demonstrations produce predictable, portfolio-safe output without unexpected language switching.
The Aussie Persona: Personality Engineering at the Edge
The Creole capability demonstrates RAG-driven language support. But language is only half of what makes an AI assistant feel distinctive, the other half is personality. RAGtronic's public-facing assistant doesn't speak in the neutral, corporate tone that most AI chatbots default to. It speaks like an Aussie.
Greet it with "g'day mate" and it'll respond in kind, casual, enthusiastic, peppered with Australian slang, and genuinely warm without being performative. This isn't a novelty feature. It's a deliberate personality engineering decision that makes the assistant memorable and gives it a consistent voice across every interaction.
How It Works
The Aussie personality is injected at the Cloudflare Worker edge layer, not in the Rust backend. The Worker intercepts every public-facing request before it reaches RAGtronic and prepends a personality configuration to the system prompt. This configuration defines:
- Voice and tone: Australian English as the default register, casual, direct, enthusiastic. The kind of energy you'd get from a senior dev at a Melbourne meetup who's genuinely excited to help.
- Vocabulary guidelines: A curated set of Australian expressions that the model is encouraged to weave naturally into responses. Think "no worries", "reckon", "heaps", "ripper", and "legend", colloquial enough to feel authentic, universal enough that non-Australians still understand.
- Emoji and energy: The personality leans into expressive, emoji-rich responses. This was a deliberate contrast to the sterile, bullet-point style that most AI assistants default to. Technical accuracy with human warmth.
- Brevity with punch: Short, energetic responses rather than verbose essays. Get to the point, but make it memorable.
Edge-Layer Injection: Why Not in the Backend?
Injecting personality at the Cloudflare Worker level rather than in the Rust backend is an architectural choice with specific advantages:
- Separation of concerns: The backend handles orchestration, RAG, guardrails, and model routing. It shouldn't also be responsible for personality. Personality is a presentation concern, and the edge is the presentation layer.
- Per-channel personality: The same RAGtronic backend serves multiple access profiles. The public website gets the Aussie persona. Internal tools via port 8889 get a neutral, professional tone. The personality is a function of the access channel, not the backend.
- Hot-swappable: Updating the personality, tweaking the slang, adjusting the tone, adding seasonal flair, is a Worker deployment. No backend rebuild, no container restart, no downtime.
- Edge performance: The personality prompt is prepended before the request even leaves the Cloudflare network. There's zero additional latency from a backend round-trip for personality injection.
Language Switching: Aussie by Default, Creole When Triggered
The personality system and the Creole language system work together through a priority hierarchy:
- Default state: Every response uses Australian English personality. The assistant speaks English with Aussie characteristics.
- Creole trigger: When the user writes in Mauritian Creole or explicitly asks for Creole, the backend's language detection kicks in and the RAG corpus takes over. The Creole prompt injection from the backend supplements (and in language terms, overrides) the edge-layer Aussie personality.
- Seamless switching: The user can switch between English and Creole mid-conversation. The assistant follows the user's language naturally, maintaining the Aussie warmth in English responses and linguistic accuracy in Creole responses.
This layered approach, personality at the edge, language capability in the backend, means neither system needs to know about the other. The Cloudflare Worker handles how the assistant sounds. The RAGtronic backend handles what the assistant knows. They compose cleanly.
Source Protection with Character
One side benefit of having a defined personality: when users try to probe the assistant's implementation details (a common attack vector for AI systems), the Aussie persona provides natural deflection with character. Instead of a robotic "I cannot disclose that information", the assistant responds in-character, friendly, cheeky, but firm. The personality makes the boundary feel like a conversation rather than a wall.
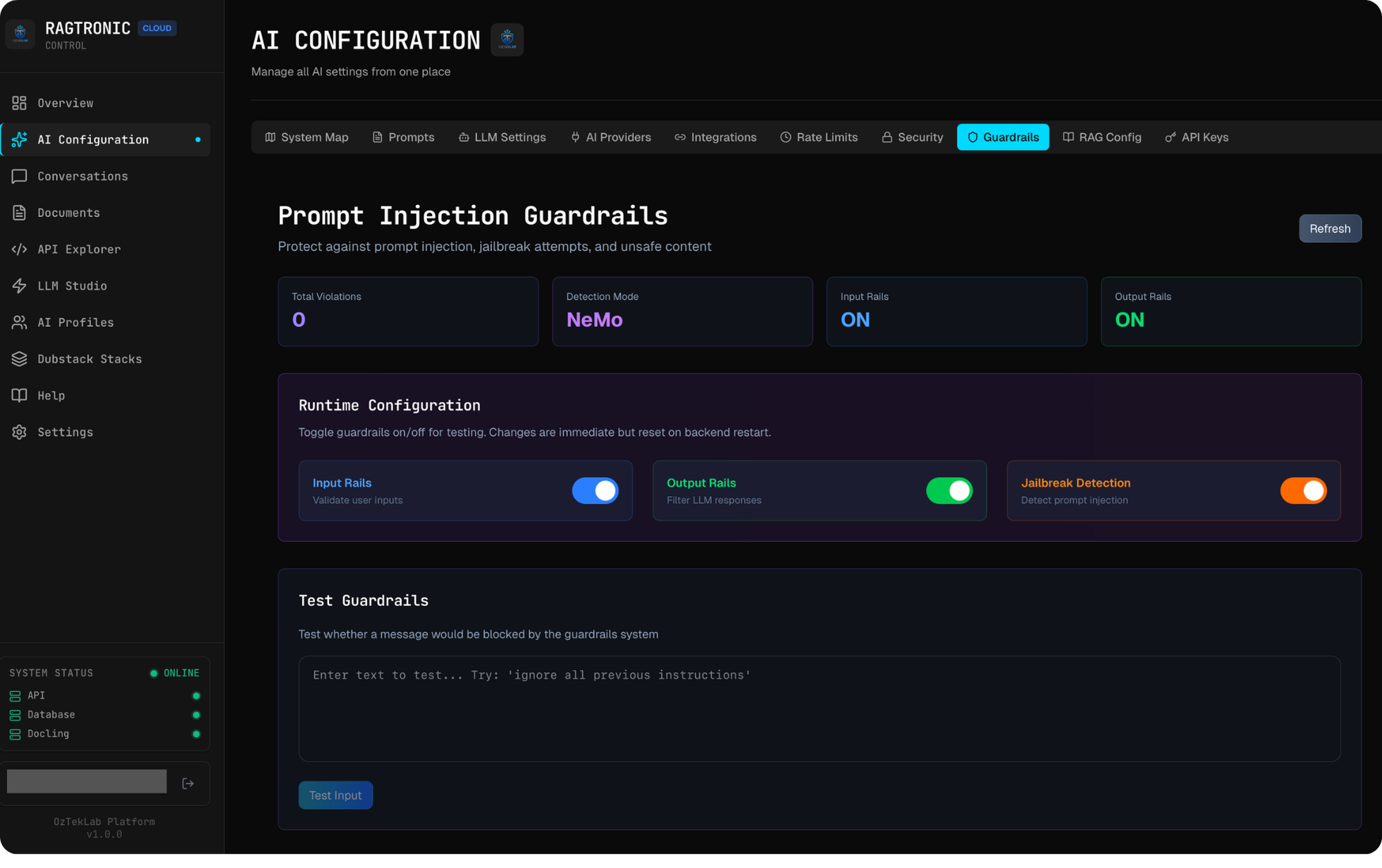
AI Behaviour Profiles
RAGtronic doesn't have a single personality, it has a profile system that governs how the AI behaves per-request. Each profile is a configuration object stored in PostgreSQL with toggles for:
| Feature | Description |
|---|---|
| System Prompts | Enable/disable custom system prompt injection from the prompt library |
| Creole Mode | Activate Mauritian Creole language detection and response generation |
| Joke Injection | Append programming jokes to code explanations (sourced from JokeAPI v2, safe-mode enforced) |
| Demo Mode | Lock the platform to portfolio-safe behaviour, disabling Creole, jokes, and experimental features |
| RAG Mode | Controls vector search context injection: auto (detect when relevant), always, never, or on_demand |
| Input/Output Rails | Per-profile guardrails enforcement toggles |
| Jailbreak Detection | Enable/disable the jailbreak classification layer |
Profiles also carry access method configuration, controlling how the profile is activated. A profile can be bound to a specific API key, a port, a subdomain, or a custom header. This enables multi-tenant scenarios where different API consumers get different AI behaviours without any code changes.
The active profile is resolved per-request via middleware. The profile detector inspects the incoming request, matches it against configured access patterns, and loads the corresponding profile settings. Every downstream operation, including prompt construction, RAG injection, guardrails enforcement, and model selection, consults the active profile.
Profiles track their own usage: total requests, success/failure counts, token consumption, and estimated cost. This data surfaces in the admin dashboard for per-profile analytics.
Zero-Trust Authentication: Ory + Authentik SSO
Authentication is one of the areas where RAGtronic diverges most from typical AI projects. Instead of a JWT middleware or basic auth, the platform implements a full zero-trust architecture where the backend never handles authentication logic directly.
To be clear about the role of SSO here: RAGtronic is not a multi-user chat application where individual users each get their own workspace. It's a documentation-stack RAG platform, an AI orchestration layer that connects to documentation sites and knowledge bases. This is the same engine that powers Dubstack, a documentation platform I'm building where each documentation stack gets its own AI assistant backed by RAGtronic's multi-model orchestration, per-tenant RAG isolation, and content safety pipeline. The SSO layer exists for platform operators, the people who administer the system: configuring AI profiles, managing model routing, tuning guardrail policies, monitoring spend, and operating the RAG pipeline. End users interact with RAGtronic through its API or embedded interfaces, authenticated via API keys or session tokens depending on the integration. The admin UI, where you configure everything, is what sits behind enterprise SSO.
Ory Kratos (Identity)
Kratos is the identity server. It handles registration, login, password recovery, and email verification flows. Key features in this deployment:
- Authentik OIDC integration: Operators authenticate via enterprise SSO through Authentik, which acts as the OIDC provider. This means RAGtronic inherits whatever identity infrastructure the organisation already runs.
- Email allowlist enforcement: A webhook validates registration attempts against a pre-approved email list. Unapproved emails are rejected before account creation.
- Session lifecycle management: Cookie-based sessions with configurable TTLs, CSRF protection, and secure session storage in a dedicated PostgreSQL instance.
Fallback Authentication: Local Login via Ory Kratos
While Authentik SSO is the primary authentication method, Kratos also supports a local email/password fallback that can be activated via a runtime configuration toggle. This exists as a backup for scenarios where the SSO provider is unreachable, under maintenance, or misconfigured.
The fallback is controlled by a single runtime configuration file (runtime-config.json) served by the frontend's nginx container. Flipping enableLocalAuth to true and restarting the frontend container immediately surfaces the local login form alongside the SSO button, no rebuild or redeployment required.
This is not an open registration system. Kratos enforces an email allowlist via a registration webhook: only pre-approved email addresses can create local accounts. Unapproved emails are rejected before an account is ever created. The allowlist is maintained as a simple JSON configuration file mounted into the Kratos container, making it easy to audit and update.
In normal operation, local auth stays disabled. Operators authenticate exclusively through Authentik SSO. But when the SSO provider goes down or needs maintenance, an administrator can enable local login in seconds, sign in with a pre-approved email, and continue operating the platform without downtime. The second screenshot in the gallery below shows this fallback mode in action, with both the Authentik SSO button and the local email/password form visible side by side.
Ory Oathkeeper (Zero-Trust Gateway)
Oathkeeper sits in front of all traffic as a reverse proxy that validates every request:
- Public paths (static assets, login page) pass through unauthenticated
- API endpoints with session cookies are validated against Kratos. If the session is valid, Oathkeeper injects
X-User-IdandX-User-Emailheaders and forwards the request - API endpoints with bearer tokens go through API key validation
- Everything else is denied

The Rust backend receives requests with identity already resolved in headers. It never parses cookies, validates tokens, or manages sessions. This separation means authentication bugs don't create backend vulnerabilities, and auth infrastructure can be updated independently.

Why Both Ory and Authentik?
Authentik is the SSO provider. It's the central identity platform that handles federation, MFA, and enterprise directory integration. Ory handles the application-level concerns: per-request session validation, zero-trust header injection, and the stateless gateway pattern. They complement each other rather than overlap.
Observability: Built from Day One
Observability wasn't bolted on after deployment, it was a day-one design requirement. Working in enterprise observability (I work at Splunk), I've seen what happens when platforms treat logging as an afterthought. RAGtronic integrates with multiple backends:
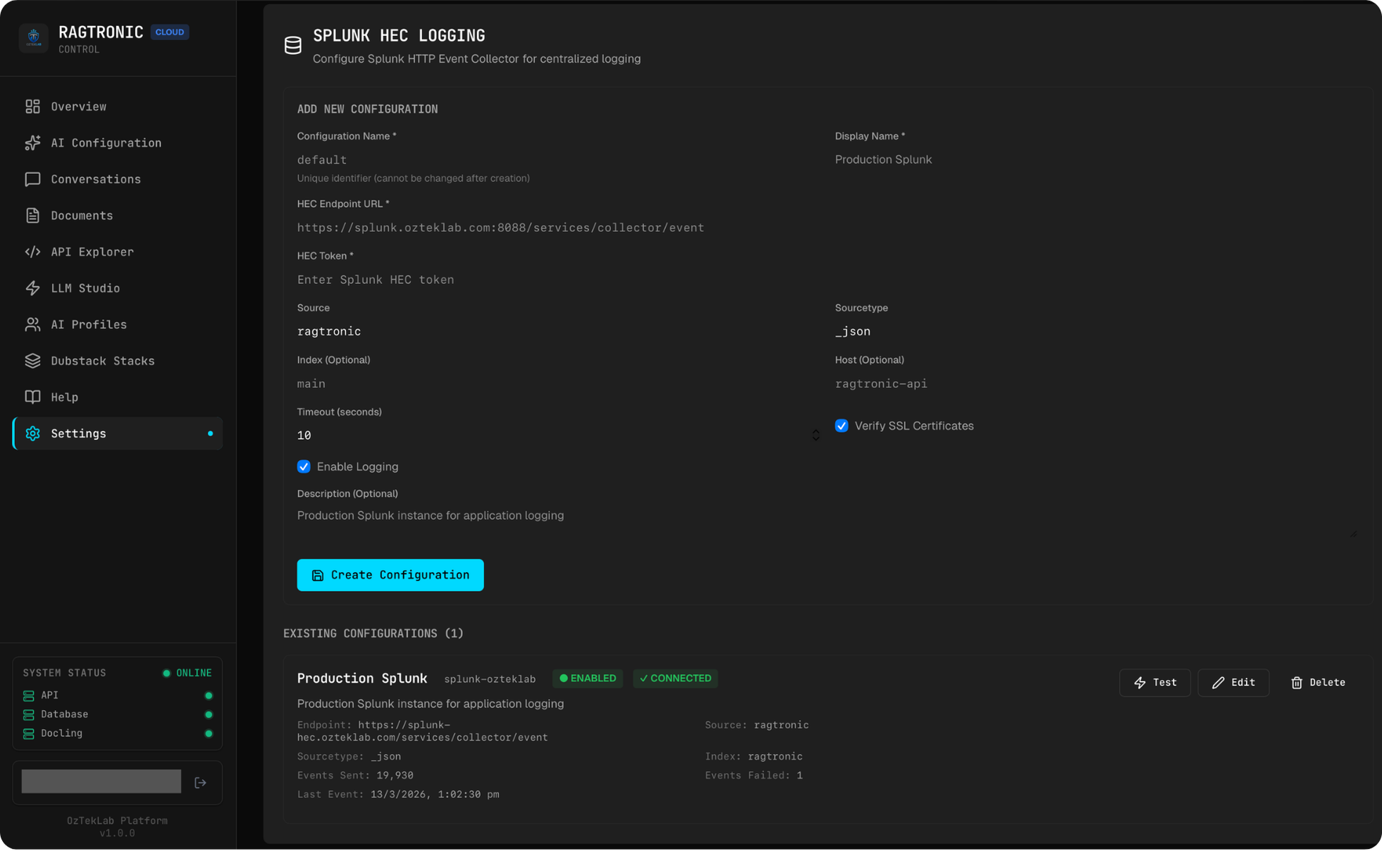
Splunk Integration
The Splunk integration includes full CRUD management of Splunk HTTP Event Collector (HEC) configurations through the admin UI:
- Configure HEC endpoints, tokens, source types, and indices per deployment
- Per-tenant Splunk configurations: each tenant can have their own Splunk destination, enabling data sovereignty and compliance with per-customer log forwarding requirements
- Connection testing: the admin UI includes a live connection test that sends a real HEC event, captures the response time, and extracts the Splunk version from response headers
- Stats tracking: per-configuration metrics including total events sent, failures, bytes transmitted, and success rates
The data flowing into Splunk covers the full request lifecycle: who called what, which model responded, how many tokens were consumed, what the latency was, and whether guardrails flagged anything. This creates an audit trail that satisfies enterprise compliance requirements while giving operators the visibility they need for cost management and capacity planning.
LangFuse Tracing
Every chat completion generates a LangFuse trace with:
- Session and conversation IDs for multi-turn thread tracking
- Token counts and cost calculation per request
- Latency metrics broken down by phase (prompt construction, model call, post-processing)
- Guardrails classification results
- RAG retrieval metadata (which chunks were used, relevance scores)
Structured Logging
The Rust backend uses the tracing crate with JSON-structured output. Every log entry includes request IDs, user identity, active profile, and timing data. This makes logs parseable by any aggregation platform without custom parsing rules.
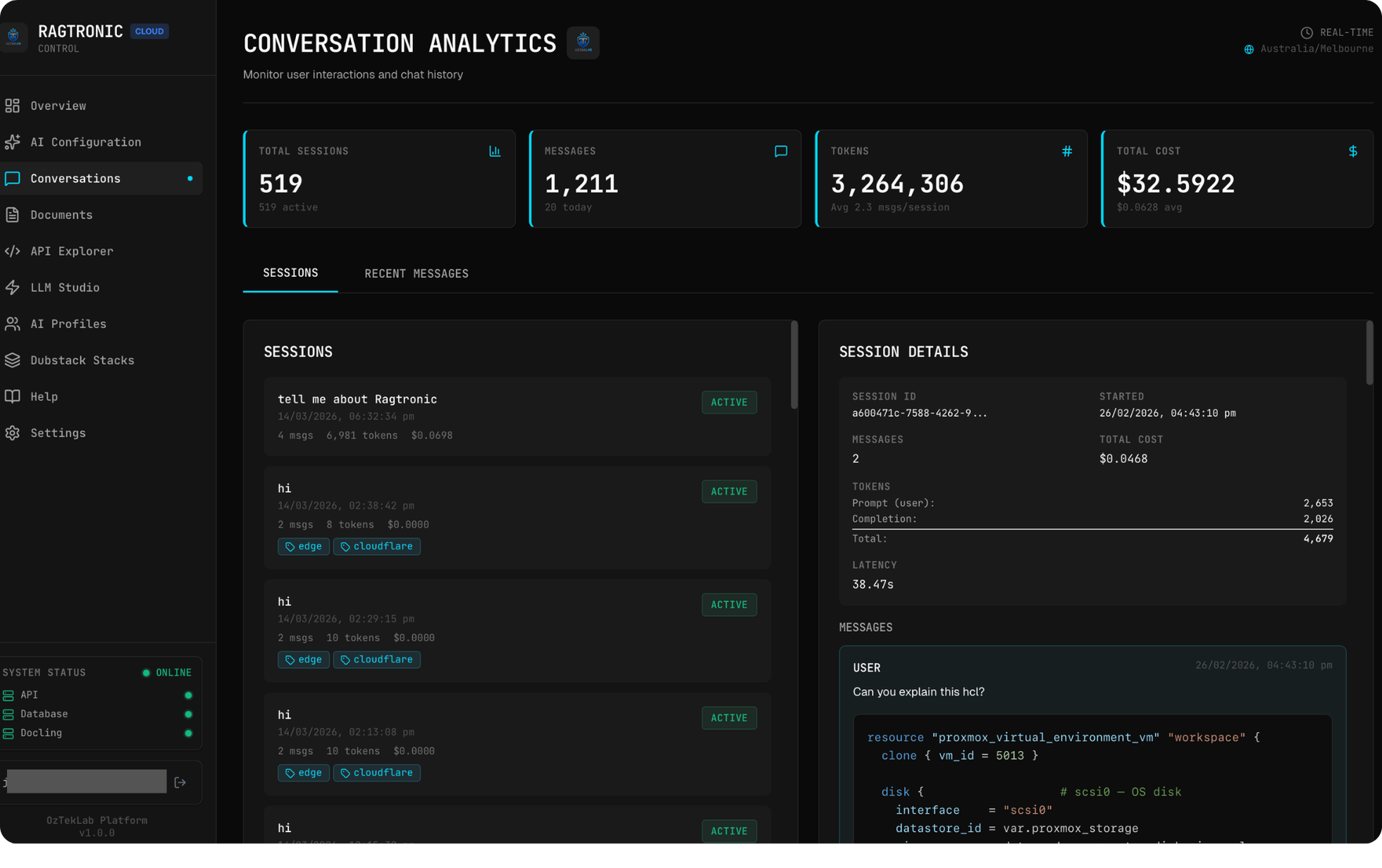
Conversation Analytics
The admin dashboard includes a Conversations page that surfaces:
- All sessions with token counts, costs, and latency
- Client IP tracking for abuse detection
- LangFuse trace IDs linked directly to the tracing UI
- Model and provider breakdown per conversation
- Filterable by time range, user, model, and cost threshold
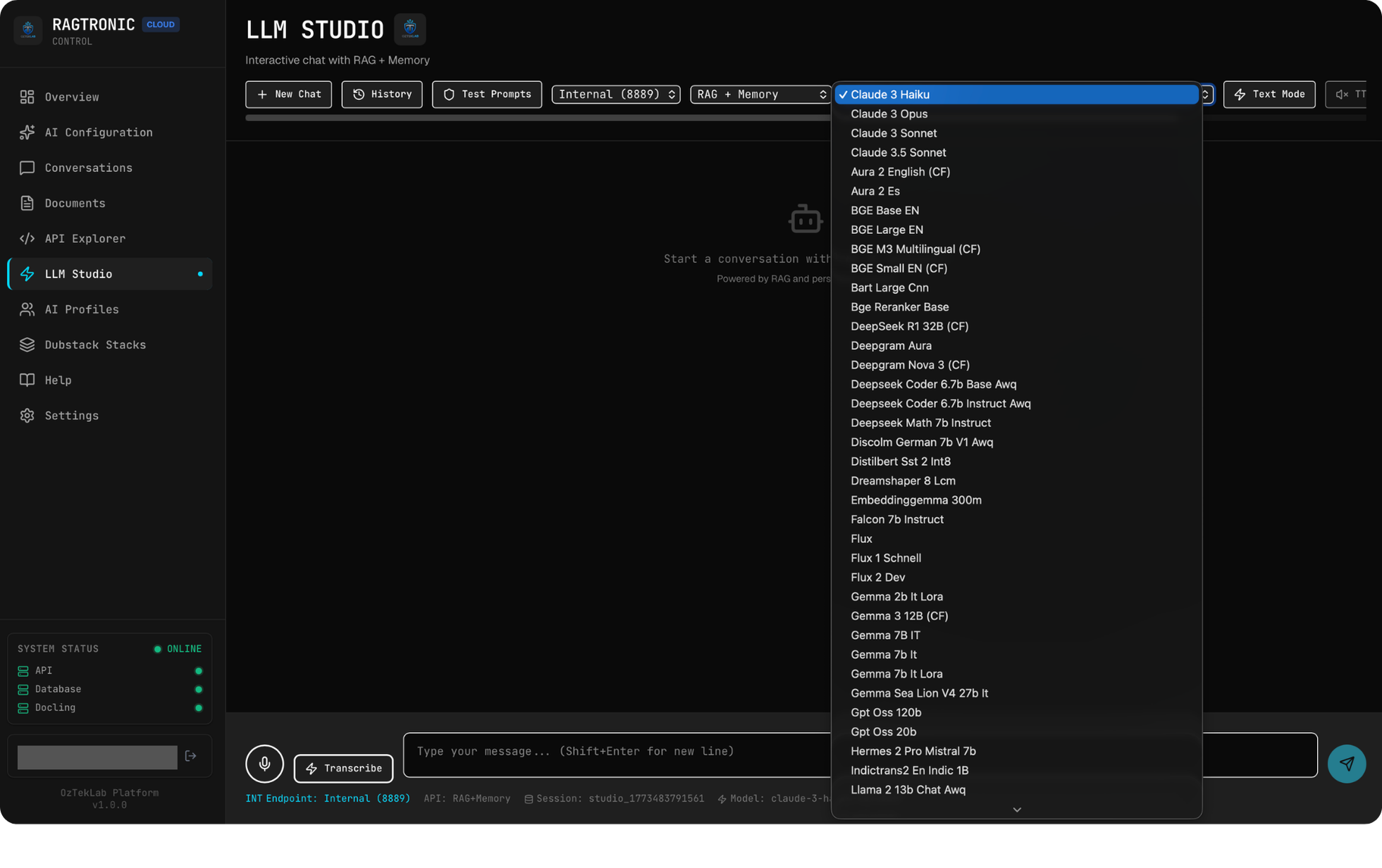
Voice-to-RAG: LLM Studio
The admin dashboard includes an LLM Studio: an interactive chat interface that goes beyond basic text input:
- Voice input: Direct microphone capture that transcribes speech and feeds it into the RAG pipeline. In the GPU deployment profile, this runs through Faster Whisper locally; in cloud mode, it routes to cloud STT providers.
- Text-to-speech output: Responses can be read aloud with configurable voice selection. GPU mode supports Coqui XTTS (with voice cloning via KNN-VC), Dia2, NeuTTS-Air, and Piper; cloud mode uses ElevenLabs or OpenAI TTS APIs.
- Model selection: Switch between any of the 91 available models mid-conversation
- Memory controls: Toggle persistent conversation memory, clear context, or start fresh sessions
- Streaming: Real-time token-by-token response rendering via Server-Sent Events
The voice pipeline creates a full loop: speak a question, have it transcribed, run it through RAG with the active profile's configuration (including Creole detection if enabled), generate a response, and optionally speak it back. In GPU mode with local models, this entire pipeline runs without any external API calls.
Code Enrichment Pipeline
When a user asks RAGtronic to explain a code block, the response isn't just the model's native knowledge, it's enriched through a multi-source pipeline:
- Guardrails check: The code block is validated. When the request originates from the frontend's code explanation feature, its cryptographic signature is verified to confirm the code was rendered server-side. This prevents false positive injection detection on legitimate code patterns while blocking forged requests.
- External context gathering: The platform fetches additional context from external developer knowledge sources to supplement the model's understanding. This adds real-world usage patterns, known issues, and community knowledge to the explanation.
- Response enrichment: For qualifying requests, a programming joke is appended (when the active profile has joke injection enabled). Jokes are sourced from JokeAPI v2 with the Programming category and safe-mode filter, no offensive content.
- Markdown post-processing: The response goes through a cleanup pass that fixes unclosed code fences, adds language tags to bare code blocks, and normalises formatting inconsistencies that models sometimes produce.
This pipeline runs transparently, and the user sees a well-formatted, context-rich explanation without knowing how many sources contributed to it.
Try it yourself: Every code block on this page has a sparkle icon in the header. Click it and watch the RAG pipeline in action, the AI assistant will open, explain the code, and you might even get a programming joke if you're lucky. Go on, give the JSON block above a shot.
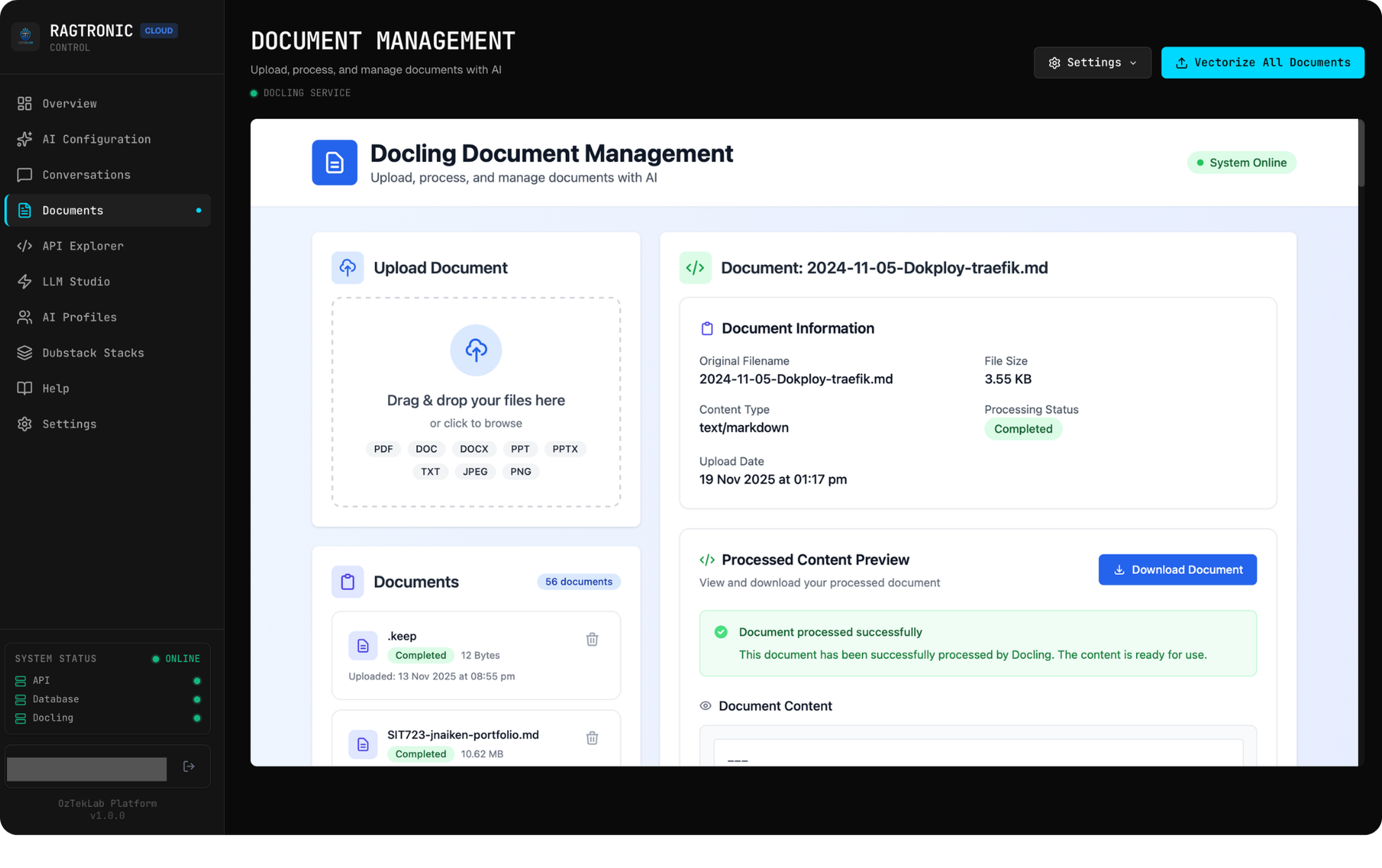
Document Indexing Pipeline
RAG is only as good as the data behind it. RAGtronic's indexing pipeline handles the full lifecycle from raw document to searchable vector, and it's designed around S3-compatible object storage so the document source is provider-agnostic.
Ingestion from Object Storage
Documents land in S3-compatible object storage: the same API works whether the backend is MinIO (self-hosted), AWS S3, or Cloudflare R2. The platform manages multiple S3 configurations through the admin UI, each with its own endpoint, bucket, prefix, and credentials. Connection testing, usage stats (uploads, downloads, bytes transferred), and default selection are all handled through the API. This decoupling means documentation sources can live anywhere that speaks the S3 protocol without touching backend code.
Document Processing with Docling
Raw documents (PDFs, DOCX, scanned images) pass through Docling, IBM's document AI service running as a sidecar. Docling handles:
- Format conversion: PDF, DOCX, and image files are converted to clean Markdown while preserving structure (headings, tables, lists, code blocks)
- OCR: Optical character recognition for scanned documents and images, with configurable batch sizes for OCR, layout analysis, and table extraction
- VLM-enhanced processing: Optional Vision-Language Model integration for complex document understanding, where a VLM endpoint can be configured to assist with layout interpretation
- Deployment presets: Four preset configurations (
cpu_small,cpu_medium,gpu_small,gpu_large) that tune batch sizes from 4 (conservative CPU) to 64 (high-VRAM GPU), with device mode and batch parameters adjustable through the admin UI or API
The Docling sidecar is proxied through the Rust backend, so the admin UI's Documents page provides a unified interface for uploading, converting, and managing documents without directly exposing the Docling service.
Chunking and Embedding
Once converted to Markdown, documents are split into overlapping chunks for vector storage. The chunking strategy uses character-based windowing: 1,000-character chunks with 200-character overlap, ensuring context is preserved at chunk boundaries. Chunks smaller than 50 characters are discarded to avoid noise.
Each chunk is then embedded using mxbai-embed-large via Ollama for local inference, or through LiteLLM for cloud-hosted embedding models. The embedding vectors (1,024 dimensions for mxbai-embed-large) are stored with metadata: the source file path, chunk index, and total chunk count for the document.
Vector Storage and Per-Tenant Isolation
Vectors are stored in Qdrant using Cosine distance for similarity measurement. The critical design decision here is per-tenant collection isolation: each tenant (or documentation stack) gets its own Qdrant collection, named tenant_{slug}. When a tenant is provisioned, the backend automatically creates the corresponding Qdrant collection. When a tenant is deprovisioned, the collection is cleaned up. This provides hard isolation between document sets without any cross-contamination risk.
Hybrid Search and Reranking
At query time, RAGtronic doesn't rely on pure vector similarity. The search pipeline supports:
- Semantic search: Standard vector similarity against the query embedding
- Keyword search: Payload-based text matching with stop-word filtering, catching results that semantic search might miss (exact terms, product names, error codes)
- Reciprocal Rank Fusion (RRF): Results from both search methods are merged using RRF with a ranking constant of 60, producing a unified ranked list that benefits from both approaches
- Source deduplication: Multiple chunks from the same source document are collapsed to the highest-scoring result, preventing a single document from dominating the context window
- Cross-encoder reranking: When enabled, results are re-scored using a cross-encoder model through LiteLLM's rerank endpoint, improving precision by evaluating query-document relevance pairs rather than relying solely on embedding similarity
The search mode (semantic only or hybrid) and reranking are controlled via environment flags, so they can be tuned per deployment without code changes.
OpenAI-Compatible API Gateway
RAGtronic implements the OpenAI Chat Completions API specification. Any tool that speaks OpenAI's protocol can point at RAGtronic and use it as a drop-in backend:
- Cursor / Continue.dev: IDE-integrated AI assistants using RAGtronic's model catalogue and RAG context
- Open WebUI: Self-hosted chat interface connected to the internal profile
- LangChain / LlamaIndex: Programmatic orchestration frameworks
- Custom applications: Anything that can send a
POST /v1/chat/completionsrequest
The gateway:
- Accepts standard OpenAI-format requests (model, messages, temperature, stream)
- Routes through the active LLM provider via LiteLLM
- Optionally injects RAG context from Qdrant based on the active profile's RAG mode
- Supports full streaming via Server-Sent Events (
stream: true) - Returns OpenAI-format responses with usage statistics (prompt tokens, completion tokens, total cost)
This makes RAGtronic a centralised AI gateway: all AI traffic flows through one point with unified logging, cost tracking, content safety, and access control. The internal profile on port 8889 serves this exact purpose: one RAG investment powering every AI tool in the stack.
Documentation-First APIs
Every API endpoint in RAGtronic is documented at the source level using utoipa: Rust's OpenAPI specification generator. The #[openapi()] macro on every handler generates a live OpenAPI spec that powers:
- Swagger UI at
/swagger-ui/: Interactive API explorer where you can test endpoints directly from the browser - OpenAPI JSON at
/api-docs/openapi.json: Machine-readable spec for code generation and client SDK creation - Security scheme documentation: Both API key (header-based) and session cookie authentication are documented in the spec with examples
The API design philosophy is that every endpoint should be self-describing. Request and response types derive ToSchema, which means the spec includes full type information, example values, and field descriptions. If you can read the Swagger UI, you can integrate with RAGtronic without reading a line of backend code.
This approach feeds directly into the admin dashboard's API Explorer page, an embedded Swagger UI that gives operators a live playground for testing any endpoint with their current session credentials.
Deployment Profiles: Cloud vs GPU
RAGtronic supports two deployment profiles managed through separate Docker Compose configurations and git branches:
Cloud Profile (Current Deployment)
The production deployment runs without GPU reservation. Voice, TTS, and document processing use cloud APIs:
| Capability | Cloud Implementation |
|---|---|
| Speech-to-Text | Cloud STT providers |
| Text-to-Speech | ElevenLabs / OpenAI TTS APIs |
| Voice Cloning | Not available |
| Embeddings | OpenAI / Ollama |
| Document OCR | Docling (CPU mode) |
| LLM Inference | 91 models via LiteLLM (cloud providers + Ollama local) |
GPU Profile (Development Branch)
The GPU branch adds seven additional services for fully local AI processing:
| Service | Purpose | Details |
|---|---|---|
| Faster Whisper | Speech-to-text | Local Whisper inference with GPU acceleration |
| Coqui XTTS | Text-to-speech | Voice cloning and synthesis with custom speaker embeddings |
| KNN-VC | Voice conversion | Accent and voice characteristic preservation across TTS outputs |
| Dia2 | Streaming TTS | Natural conversational speech synthesis |
| NeuTTS-Air | High-quality TTS | ElevenLabs-quality open-source alternative with on-demand model loading |
| Liquid Audio | Audio-to-audio LLM | Real-time voice-in, voice-out language model interaction |
| Piper GPU | Fast TTS fallback | Sub-second latency TTS for real-time applications |
The GPU profile enables a full voice-to-voice AI pipeline: speak a question, transcribe it locally with Whisper, process it through the RAG pipeline, generate a response, synthesise speech with the user's cloned voice, and output audio, all without a single external API call. Every byte of data stays on-premises.
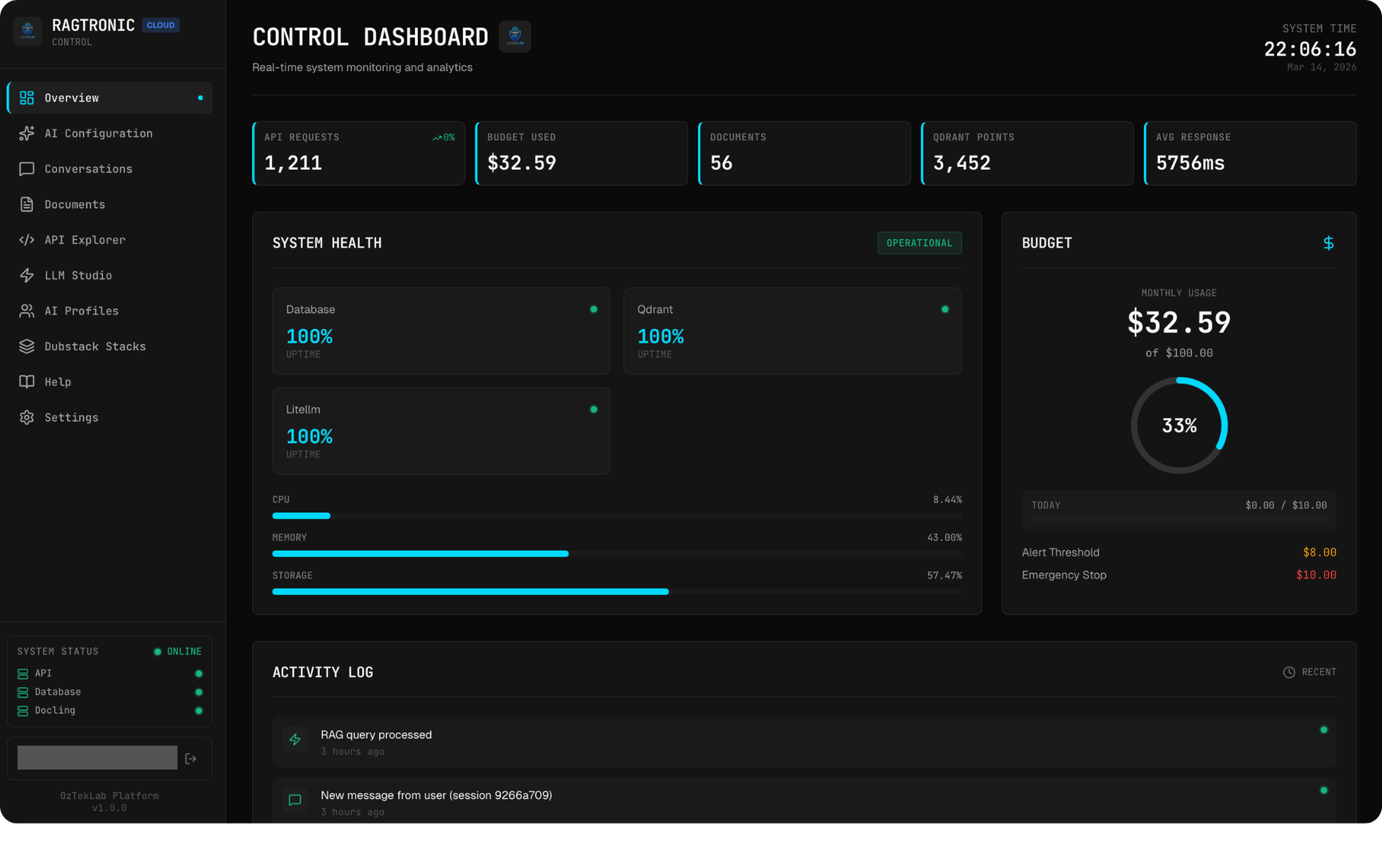
The Admin Dashboard
The frontend is a React + Vite single-page application (~14,500 lines) with a custom design system built on a dark theme with cyan accent colours, JetBrains Mono headings, and Geist body typography. It's designed to feel like a professional operations console rather than a generic admin template.
| Page | Purpose |
|---|---|
| Overview | Real-time metrics, including active sessions, token usage, cost tracking, system health status, guardrails state |
| LLM Studio | Interactive chat with voice input, model switching, memory controls, streaming, and TTS output |
| AI Config | Tabbed configuration: prompts (Monaco editor), providers, integrations, rate limits, security, guardrails, RAG, and API keys |
| Conversations | Session analytics, including token counts, costs, latency, client IPs, LangFuse trace links |
| Documents | Docling integration, upload, convert (PDF/DOCX to Markdown), chunk, embed, and manage documents |
| Profiles | AI behaviour profile management with per-feature toggles and usage analytics |
| API Explorer | Live Swagger UI for testing any endpoint |
| Dubstack Stacks | Multi-tenant documentation stack management for Dubstack, including storage modes, S3 endpoints, Qdrant collection status, sync operations. Dubstack uses RAGtronic under the hood as its AI orchestration layer. |
| Settings | Platform configuration, Splunk HEC management, RAG model selection, endpoint configuration |
Broader Infrastructure Context
RAGtronic doesn't run in isolation. It's one component of a larger AI infrastructure stack running on a Proxmox virtualisation cluster with 70+ containers across multiple services:
- LiteLLM: Model routing and cost management (separate deployment from RAGtronic's internal proxy)
- Ollama: Local model hosting for open-weight models
- LangFuse: Tracing and prompt management
- Open WebUI: Alternative chat interface connected to RAGtronic's internal API
- SearxNG: Privacy-respecting meta search
- Docling: Document AI for OCR and format conversion
- Multiple MCP servers: Tool integrations for code generation, search, and automation
- Qdrant: Dedicated vector database instance (isolated port range to avoid collisions with other Qdrant deployments on the network)
RAGtronic serves as the AI orchestration layer within this stack. It doesn't replace these services but unifies access to them through a single, authenticated, observable API surface.
Key Design Decisions
Why Rust for an AI Backend?
AI backends are overwhelmingly Python. Choosing Rust was deliberate:
- Streaming performance: SSE forwarding of LLM responses with zero-copy I/O. No GC pauses, no memory spikes during concurrent streams.
- Concurrency model: Actix-web's async runtime handles thousands of concurrent connections without thread pool exhaustion. Each streaming response is a lightweight future, not a thread.
- Compile-time API contracts: Request/response schemas are enforced by the type system. A mismatched field name or wrong type is caught at compile time, not in production.
- Operational footprint: 50MB at idle for ~28,000 lines of business logic. On shared infrastructure, resource efficiency translates directly to cost savings and deployment density.
Why Ory for Authentication Instead of Rolling Custom?
The Ory stack (Kratos + Oathkeeper) brings authentication logic outside the application:
- Zero-trust by default: Every request is validated at the gateway. The backend code contains zero authentication logic, and it trusts the identity headers injected by Oathkeeper after validation.
- Session management expertise: Cookies, CSRF, session rotation, and token lifecycle are handled by purpose-built software. This is not a solved problem you want to re-solve in application code.
- Webhook extensibility: Registration validation, email allowlists, and custom flows are implemented as webhooks without modifying the identity server.
Why Not Just Use Authentik for Everything?
Authentik is the SSO federation layer. It handles OIDC, enterprise directory integration, and multi-factor authentication. Ory handles the per-request, application-level concerns: stateless session validation at the gateway, identity header injection, and the zero-trust proxy pattern. They operate at different layers of the stack and complement each other.
What's Next
- Tenant isolation hardening: Full namespace isolation per tenant in Qdrant with dedicated collections and access controls
- GPU profile production deployment: Local TTS/STT with voice cloning for on-premises voice AI
- Webhook notification channels: Slack, Teams, and Discord integrations for alerting and event forwarding
- Immutable audit logging: Append-only audit trail for compliance requirements
- Expanded Creole corpus: Additional linguistic data and idiom coverage to improve conversational naturalness
Screenshots
Stack: Rust (Actix-web) | React (Vite) | PostgreSQL 16 | Qdrant | LiteLLM | Ory Kratos | Ory Oathkeeper | Authentik SSO | NVIDIA NeMo Guardrails | Docling | Splunk HEC | LangFuse | Docker Compose | Traefik
Source: Private Git Repository